Explore our expert-made templates & start with the right one for you.
Easily Build Powerful
Real-time Pipelines on Your Cloud Data Lake

Cloud object storage lets you affordably store large amounts of semi-structured and streaming data, such as logs, clickstreams, and IoT sensor data. However, preparing complex and continuous data for analytics using Apache Spark presents a number of challenges.
You must:
- Write jobs to ingest the batch, mini-batch or streaming data
- Hand-code tricky continuous transformation logic
- Specify and orchestrate a query execution sequence via a DAG
- Optimize the file system management including partitioning, compaction, columnarization, etc.
- Configure and coordinate multiple products, services and activities
This intricate, error-prone work requires extreme care, plus expensive and scarce big data engineers. It can take months to design, test, debug, and deploy these continuous pipelines reliably at scale.
Power Real-time Analytics over Cloud Object Storage
Upsolver makes creating real-time pipelines as easy as S-Q-L. It reduces your most difficult data engineering challenges to an SQL query combined with automation based on data lake best practices. Upsolver customers build powerful pipelines quickly, without needing “big data” skills, and run them reliably at scale, even when dealing with complex data such as nested and array fields arriving as semi-structured event streams.

Blend Streaming and Historical Data using Data Lake Indexing
Upsolver lets you combine streaming data at high volume (e.g. 100,000s of events per second) with historical batch data, and perform stateful transformations such as high cardinality joins, window or sessionization operations. Output data is always up-to-date due to incremental aggregations via data lake upserts and exactly once consistency guarantees. And performance is ensured through unique data lake indexing.

Unpack complex data
Complex data types such as nested data and arrays can be challenging to work with. Upsolver auto-detects the schema on read and visualizes it in an IDE, making it easy to flatten rich data types into a more workable format.

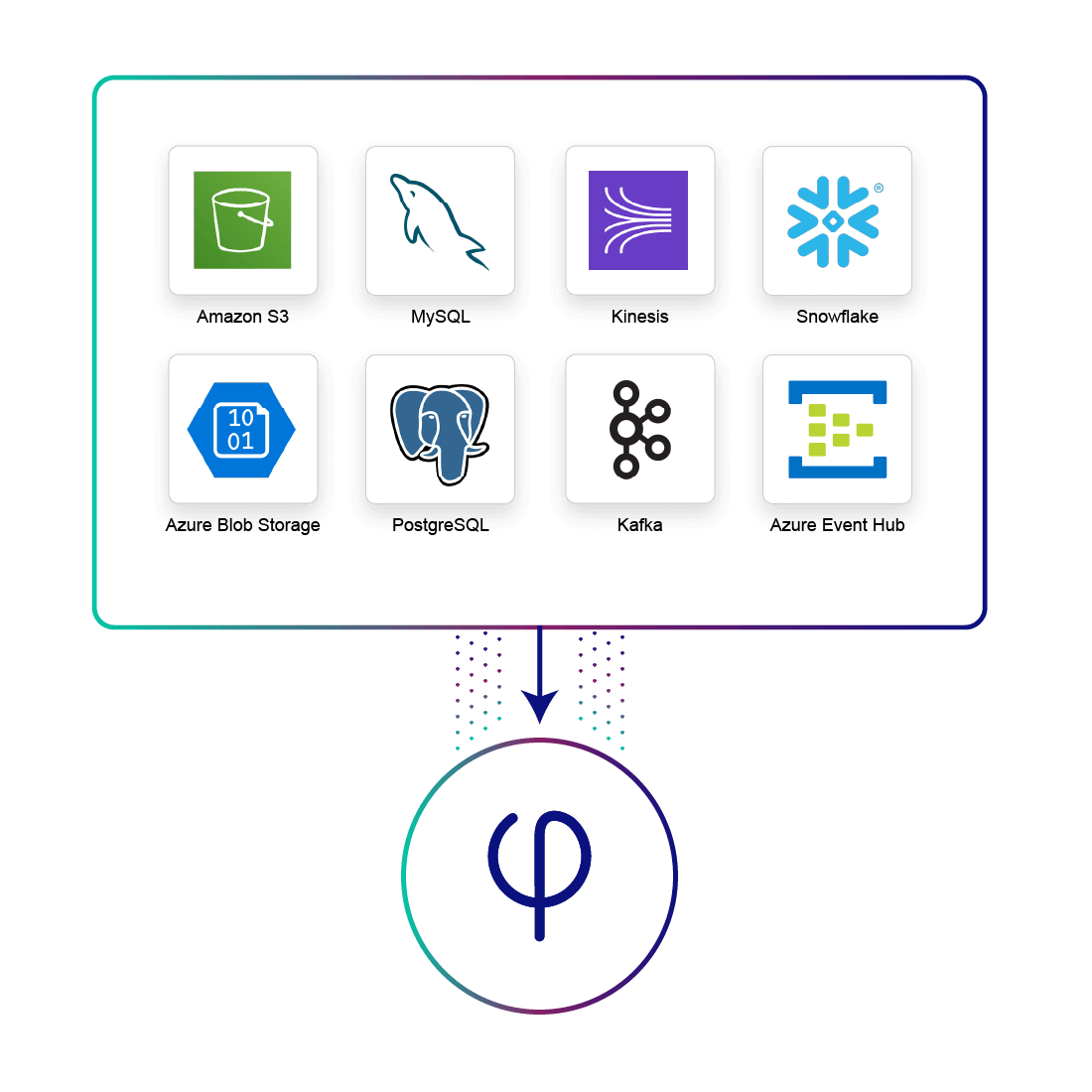
Ingest Continuous Data using Pre-built Connectors
No need to hand code ingestion as Upsolver comes with connectors for a variety of data source types:
- Stream processors such as Kafka, Kinesis and Azure Event Hub
- Log-based CDC events from databases such as MySQL, Postgres and MariaDB.
- Mini-batch files dropped into cloud object storage (e.g. S3, ADLS or GCS).
- Numerous formats are supported including Avro, Parquet, ORC, JSON, CSV, TSV and Protobuf.
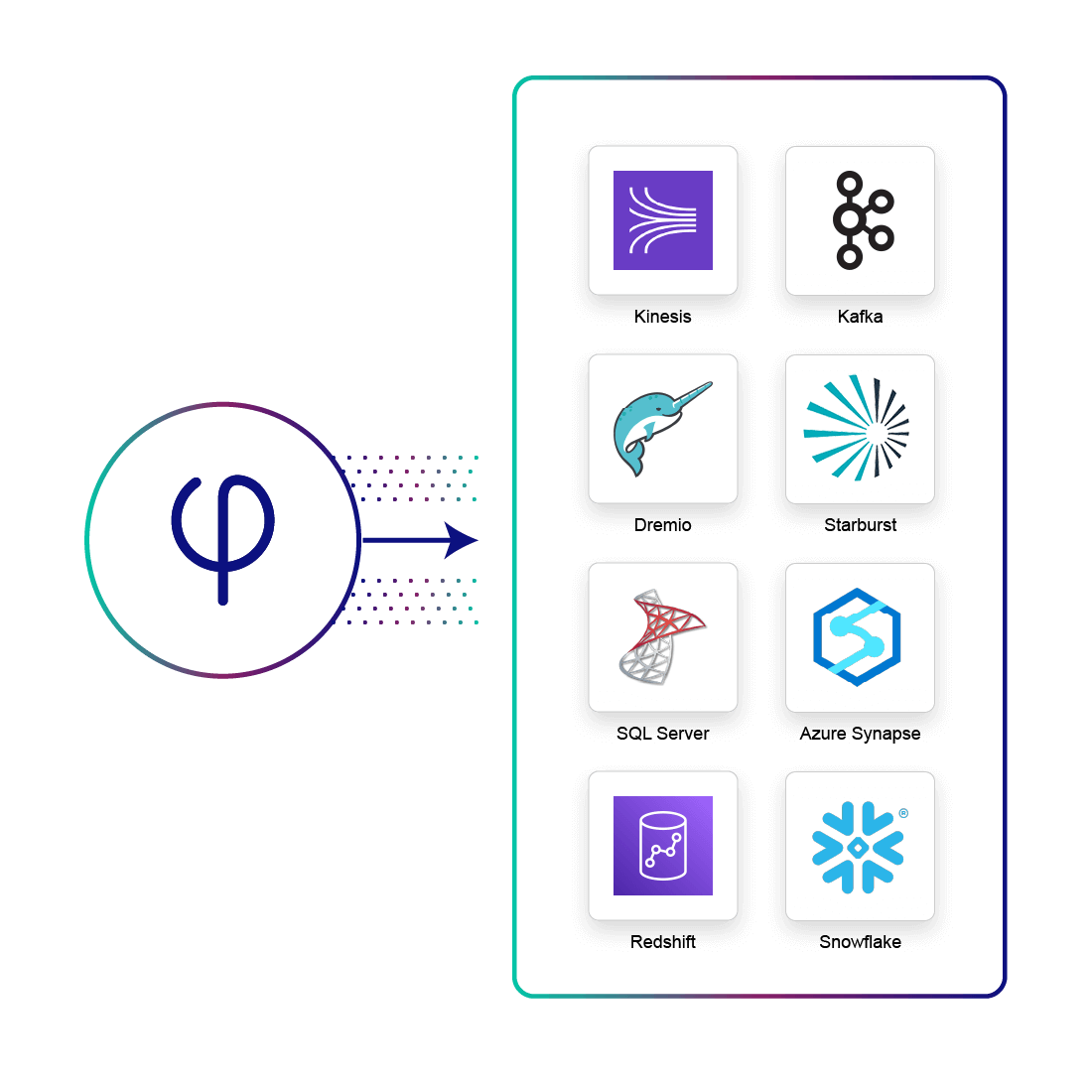
Continuous Output to Query Engines, Cloud Data Warehouses and Streaming Platforms
Upsolver pipelines output to a variety of platforms via connectors, so you can distribute data as you see fit.
- Query Parquet output tables using Athena, Redshift Spectrum, Starburst and Dremio
- Output and update tables in Redshift, Synapse or Snowflake.
- Send data to Kafka topics or Kinesis streams for downstream processing.
- UPSERTs are handled seamlessly for always up-to-date output tables
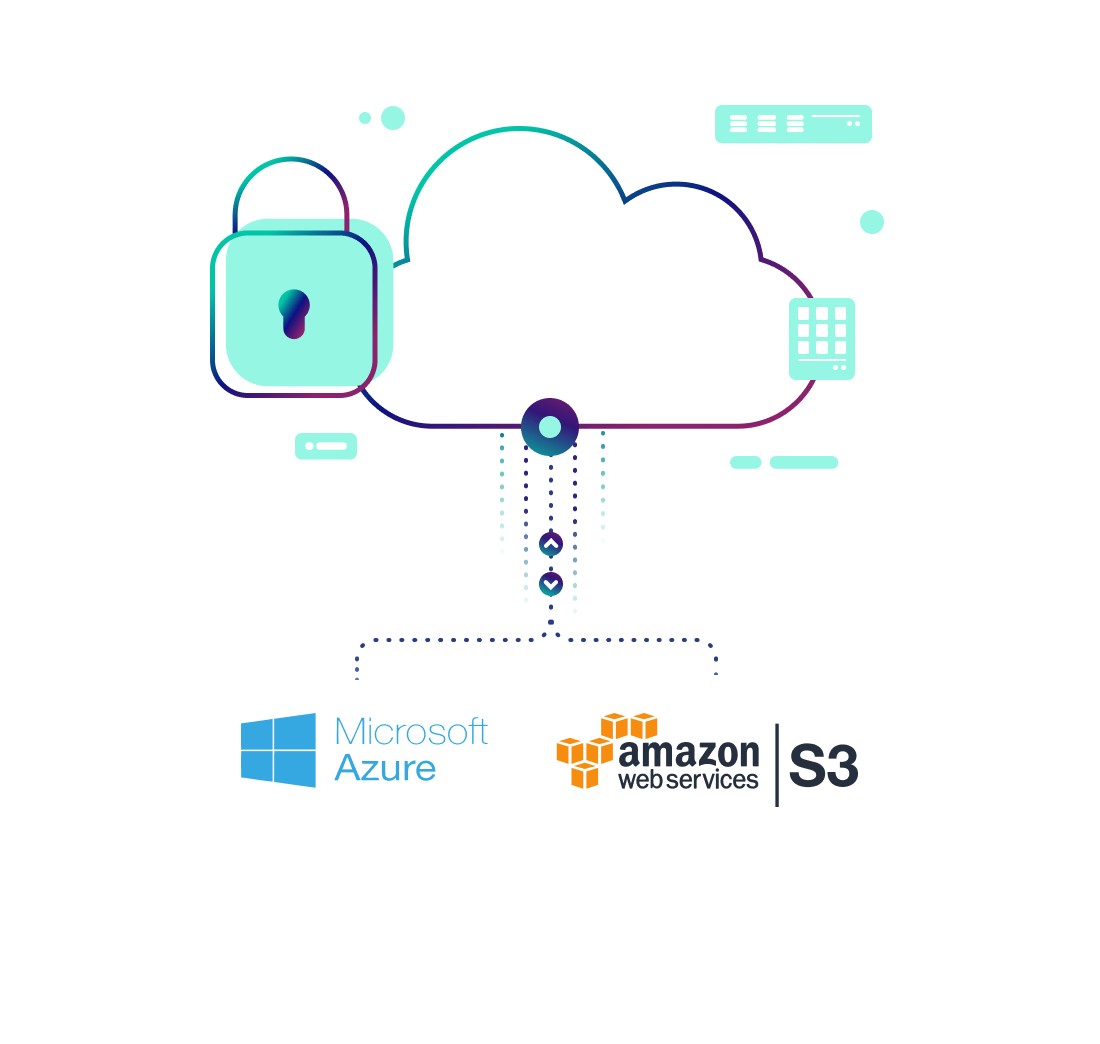
Fully Managed Infrastructure, Deployed in your VPC
- Upsolver deploys to your cloud account and accesses your raw data.
- Upsolver manages services availability and performance.
- Upsolver auto-scales based on your workload requirements, up to 1000s of nodes if needed.








Explore Upsolver your way
Try SQLake for Free
SQLake is Upsolver’s newest offering. It lets you build and run reliable data pipelines on streaming and batch data via an all-SQL experience. Try it for free. No credit card required.
Talk to a Solutions Architect
Schedule a quick, no-strings-attached with one of our cloud architecture gurus.
Customer Stories
See how the world’s most data-intensive companies use Upsolver to analyze petabytes of data.
Integrations and Connectors
See which data sources and outputs Upsolver supports natively.